Overview
The Kubeflow project is dedicated to making deployments of machine learning (ML) workflows on Kubernetes simple, portable and scalable. The goal is not to recreate other services, but to provide a straightforward way to deploy best-of-breed open-source systems for ML to diverse infrastructures. Anywhere you are running Kubernetes, you should be able to run Kubeflow.
Stages
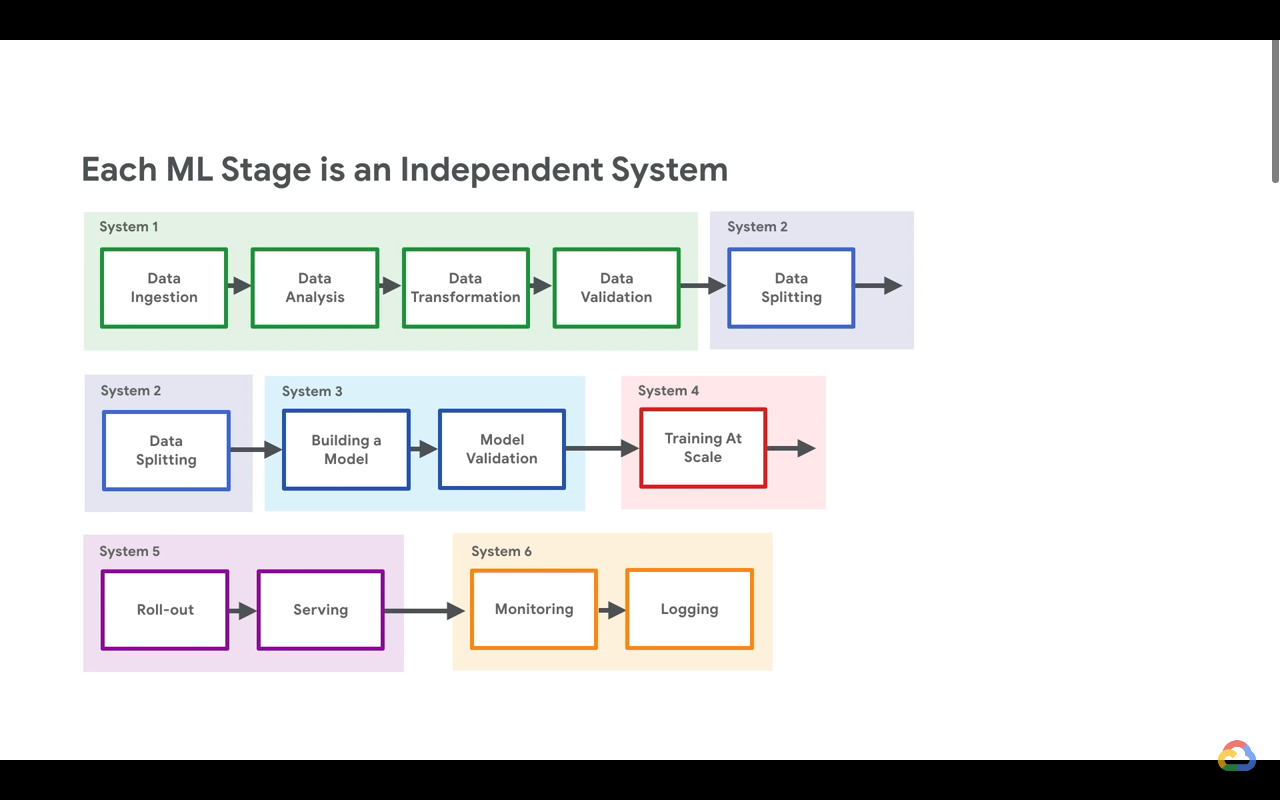
Defining ML Workflows including:
- Managing data
- Running notebooks
- Training Models
- Serving Models
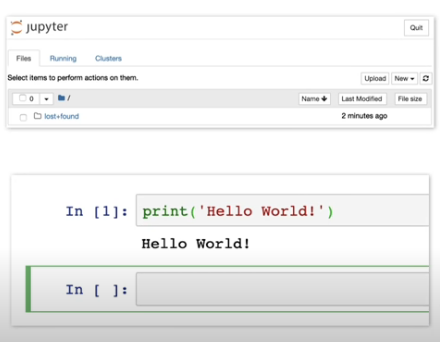
Creating a Notebook
From the Notebook menu, create a new notebook server.
Components
The central user interface (UI) in Kubeflow
Using Jupyter notebooks in Kubeflow
A powerful platform for building end to end ML workflows. Pipelines allow you to build a set of steps to handle everything from collecting data to serving your model.
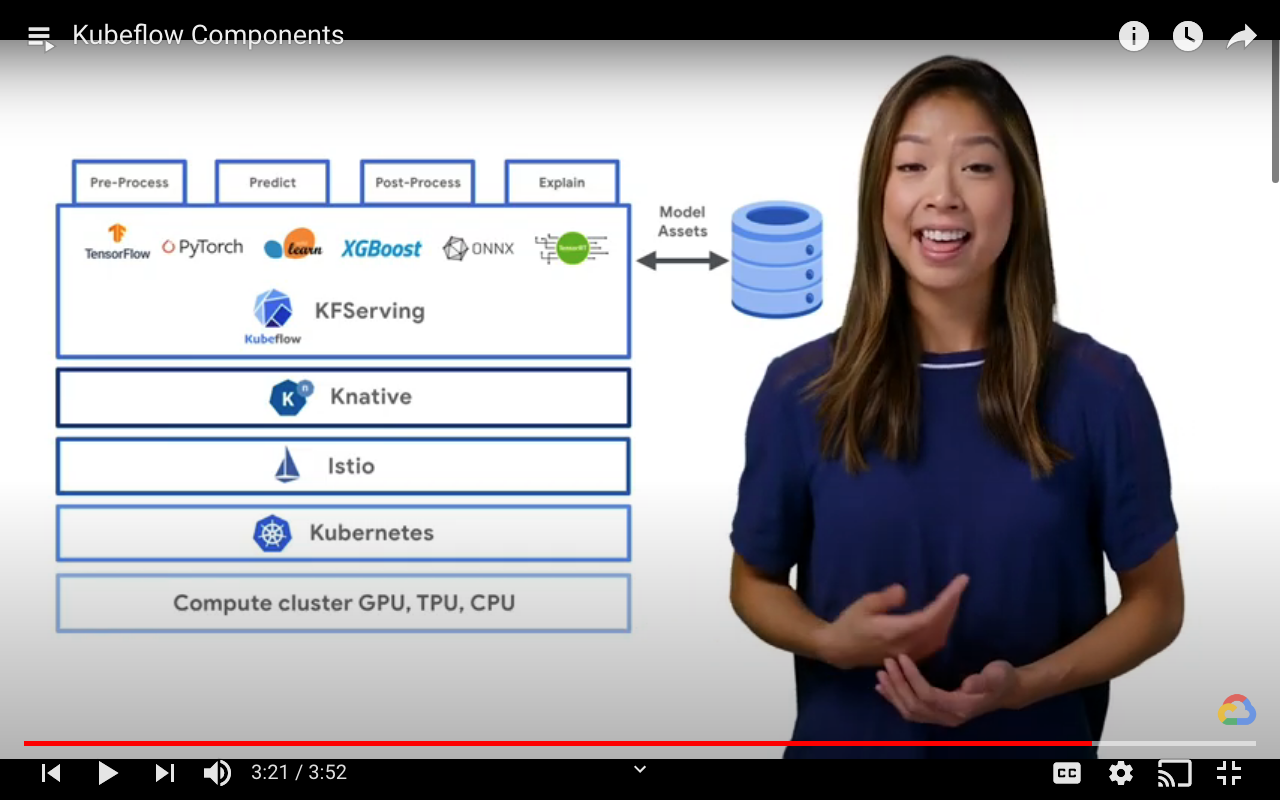
Kubeflow model deployment and serving toolkit
Katib is a Kubernetes-native project for automated machine learning (AutoML). Katib supports hyperparameter tuning, early stopping and neural architecture search (NAS).
Training of ML models in Kubeflow through operators such as Tensorflow and Pytorch.
Multi-user isolation and identity access management (IAM)
KFServing
Jupyter Notebooks
Defacto standard for data scientists for performing rapid data analysis.
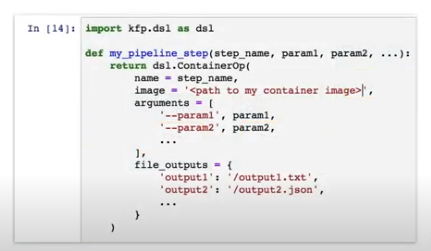
Kubeflow Pipelines
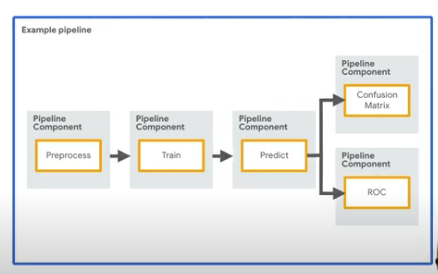
A pipeline component is one step in the workflow that performs one specific task.
Takes inputs and produces outputs.
Hyperparameter Tuning with Katib
Katib is a Kubernetes-native project for automated machine learning (AutoML). Katib supports hyperparameter tuning, early stopping and neural architecture search (NAS).
| Reference | URL |
|---|---|
| Kubeflow 101 Videos | https://www.youtube.com/playlist?list=PLIivdWyY5sqLS4lN75RPDEyBgTro_YX7x |