
Overview
Apache Kafka is an open source project for a distributed publish-subscribe messaging system rethought as a distributed commit log.
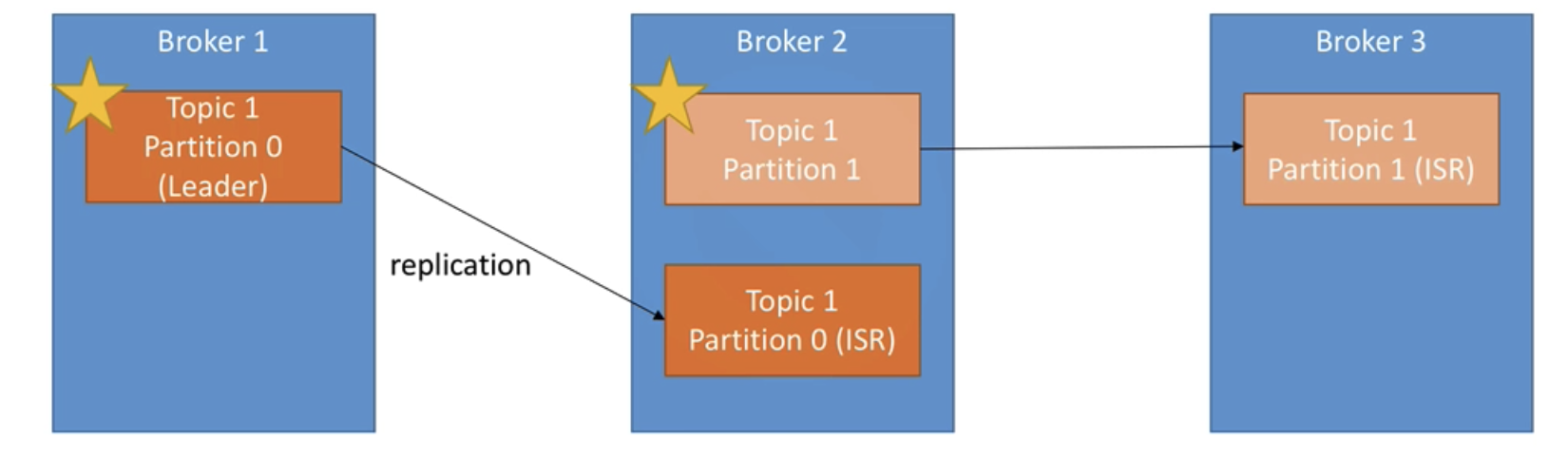
Kafka stores messages in topics that are partitioned and replicated across multiple brokers in a cluster. Producers send messages to topics from which consumers read.
Created by LinkedIn and is now an Open Source project maintained by Confluent.
Kafka Use Cases
Some use cases for using Kafka:
- Messaging System
- Activity Tracking
- Gathering metrics from many different sources
- Application Logs gathering
- Stream processing (with the Kafka Streams API or Spark for example)
- De-coupling of system dependencies
- Integration with Spark, Flink, Storm, Hadoop and many other Big Data technologies
Architecture
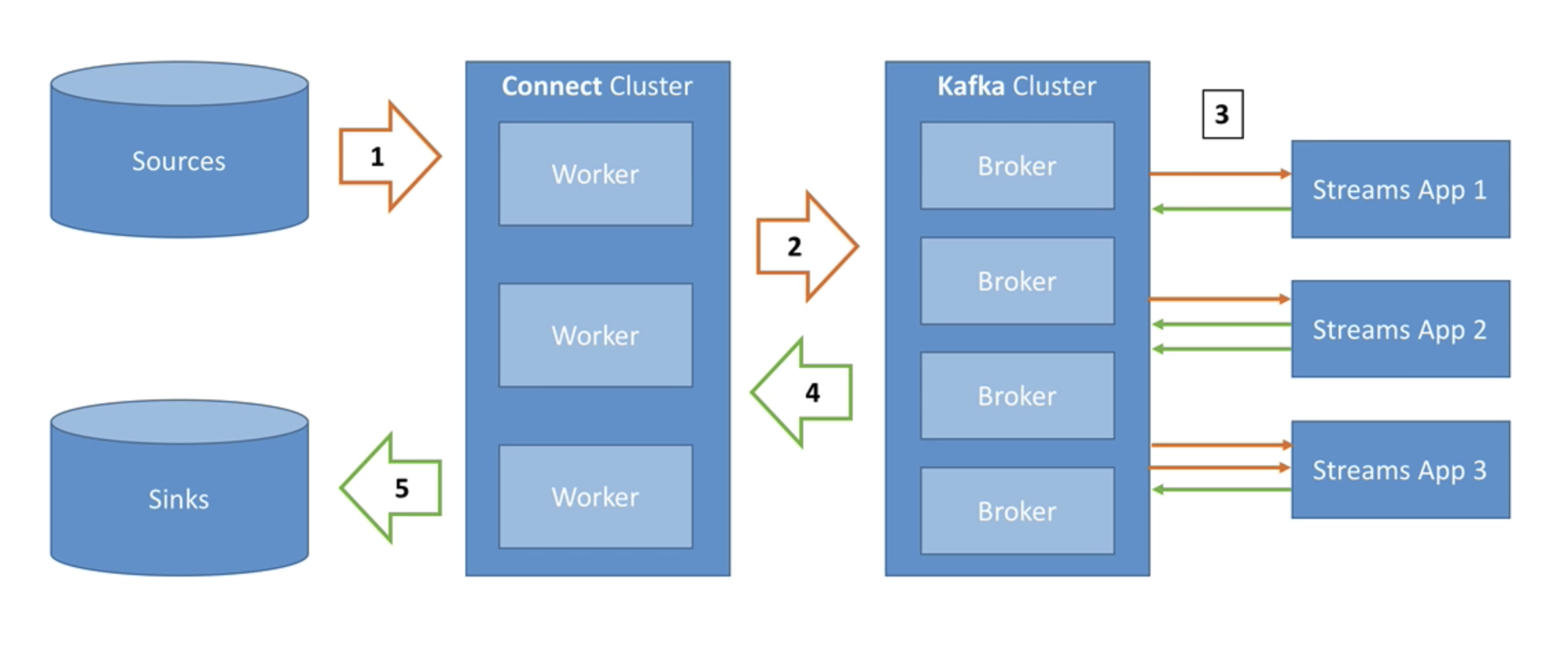
- Source Connectors pull data from sources
- Data is sent to Kafka cluster
- Transformation of topic data into another topic can be done with Streams
- Sink Connectors in Connect cluster pull data from Kafka
- Sink Connectors push data to sinks
Kafka
Topics and Partitions
Topics: a particular stream of data
- similar to a table in a database(without constraints)
- you can have as many topics as you want
- a topic is identified by it's name
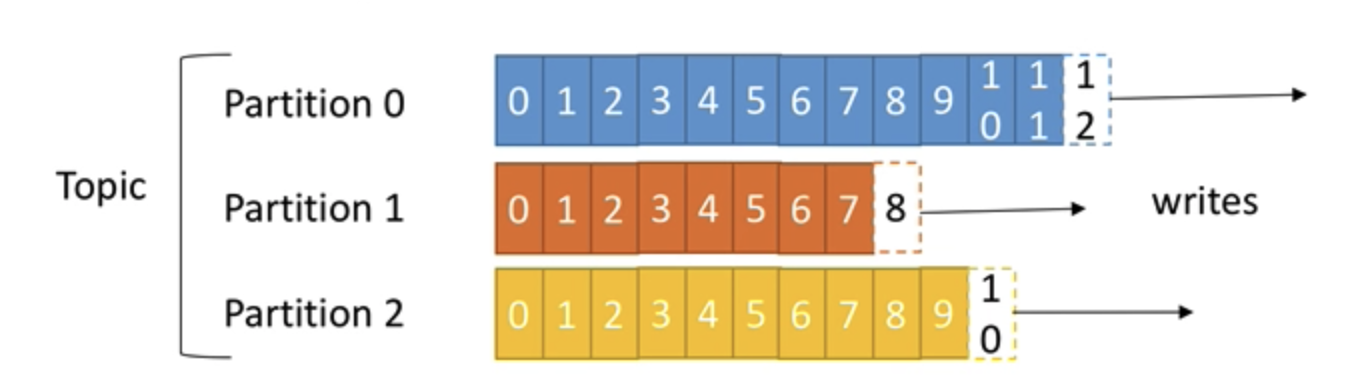
Topics are split into partitions
- each partition is ordered
- each message with a partition gets an incremental id, called offset.
- offsets are only relevant for a particular partition
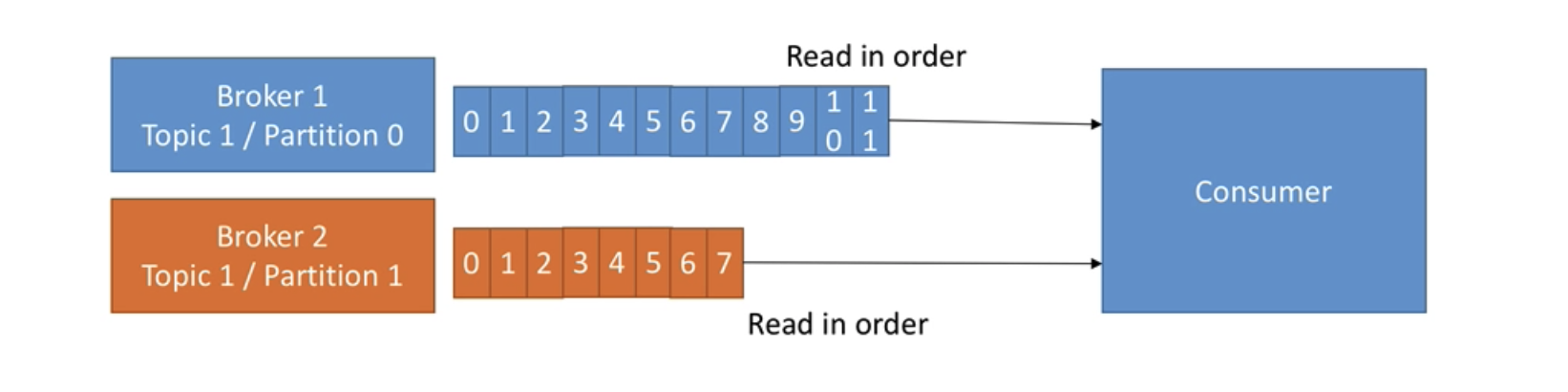
- order is guaranteed only in a partition (not across partitions)
- data is assigned to a random partition unless a key is provided
- you can have as many partitions per topic as you want
- specifying a key, ensures that your message is written to the same partition (which ensures order).
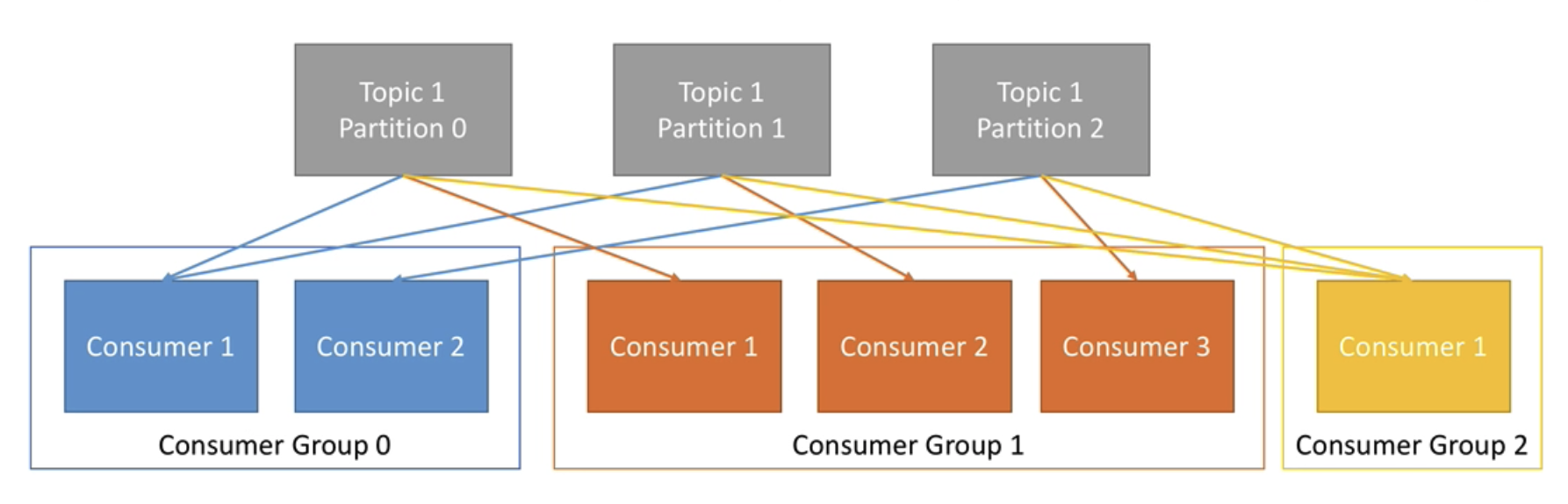
Kafka Brokers
Consumers (still relevant? - moved to Kafka Connect?)
Data Replication
- topics should have a replication factor greater than 1 (usually 2 or 3)
- this ensures that if a broker goes down, another broker can serve the data
- ISR - in-synch replica
Kafka Connect
Overview
- Source connectors to get data from common data sources
- Sink connectors to publish that data in common data sources
- Make it easy for non-experienced dev to quickly get their data reliably into Kafka
- Re-usable code!
Installation on Kubernetes
See https://github.com/confluentinc/cp-helm-charts
$ helm repo add confluentinc https://confluentinc.github.io/cp-helm-charts/ "confluentinc" has been added to your repositories > helm repo update Hang tight while we grab the latest from your chart repositories... ...Skip local chart repository ...Successfully got an update from the "confluentinc" chart repository ...Successfully got an update from the "stable" chart repository Update Complete. ⎈ Happy Helming!⎈
$ helm install confluent-kafka confluentinc/cp-helm-charts
NAME: confluent-kafka
LAST DEPLOYED: Tue Jul 27 18:42:52 2021
NAMESPACE: default
STATUS: deployed
REVISION: 1
NOTES:
## ------------------------------------------------------
## Zookeeper
## ------------------------------------------------------
Connection string for Confluent Kafka:
confluent-kafka-cp-zookeeper-0.confluent-kafka-cp-zookeeper-headless:2181,confluent-kafka-cp-zookeeper-1.confluent-kafka-cp-zookeeper-headless:2181,...
To connect from a client pod:
1. Deploy a zookeeper client pod with configuration:
apiVersion: v1
kind: Pod
metadata:
name: zookeeper-client
namespace: default
spec:
containers:
- name: zookeeper-client
image: confluentinc/cp-zookeeper:6.1.0
command:
- sh
- -c
- "exec tail -f /dev/null"
2. Log into the Pod
kubectl exec -it zookeeper-client -- /bin/bash
3. Use zookeeper-shell to connect in the zookeeper-client Pod:
zookeeper-shell confluent-kafka-cp-zookeeper:2181
4. Explore with zookeeper commands, for example:
# Gives the list of active brokers
ls /brokers/ids
# Gives the list of topics
ls /brokers/topics
# Gives more detailed information of the broker id '0'
get /brokers/ids/0## ------------------------------------------------------
## Kafka
## ------------------------------------------------------
To connect from a client pod:
1. Deploy a kafka client pod with configuration:
apiVersion: v1
kind: Pod
metadata:
name: kafka-client
namespace: default
spec:
containers:
- name: kafka-client
image: confluentinc/cp-enterprise-kafka:6.1.0
command:
- sh
- -c
- "exec tail -f /dev/null"
2. Log into the Pod
kubectl exec -it kafka-client -- /bin/bash
3. Explore with kafka commands:
# Create the topic
kafka-topics --zookeeper confluent-kafka-cp-zookeeper-headless:2181 --topic confluent-kafka-topic --create --partitions 1 --replication-factor 1 --if-not-exists
# Create a message
MESSAGE="`date -u`"
# Produce a test message to the topic
echo "$MESSAGE" | kafka-console-producer --broker-list confluent-kafka-cp-kafka-headless:9092 --topic confluent-kafka-topic
# Consume a test message from the topic
kafka-console-consumer --bootstrap-server confluent-kafka-cp-kafka-headless:9092 --topic confluent-kafka-topic --from-beginning --timeout-ms 2000 --max-messages 1 | grep "$MESSAGE"
$ kubectl get pods $ kubectl get pods NAME READY STATUS RESTARTS AGE confluent-kafka-cp-control-center-5cf9477c94-6j2tz 1/1 Running 7 49m confluent-kafka-cp-kafka-0 2/2 Running 0 49m confluent-kafka-cp-kafka-1 2/2 Running 0 38m confluent-kafka-cp-kafka-2 2/2 Running 0 38m confluent-kafka-cp-kafka-connect-7646bbff9-hhdqq 2/2 Running 3 49m confluent-kafka-cp-kafka-rest-57588d5cb5-4sfnp 2/2 Running 6 49m confluent-kafka-cp-ksql-server-5bdd6b999c-djrj2 2/2 Running 5 49m confluent-kafka-cp-schema-registry-8db5569b8-2qgm9 2/2 Running 6 49m confluent-kafka-cp-zookeeper-0 2/2 Running 0 49m confluent-kafka-cp-zookeeper-1 2/2 Running 0 38m confluent-kafka-cp-zookeeper-2 2/2 Running 0 38m
Connectors
| Connector | Type | URL |
|---|---|---|
| Azure | Kafka Sink Connector | https://www.confluent.de/hub/chaitalisagesh/kafka-connect-log-analytics |
| Fluent | Output Plugin for fluentbit | https://github.com/fluent/fluent-plugin-kafka |
| Elasticsearch | Kafka Source Connector | https://www.confluent.io/hub/dariobalinzo/kafka-connect-elasticsearch-source |
| Elasticsearch | Kafka Sink Connector | https://github.com/confluentinc/kafka-connect-elasticsearch |
| *Fluent | Output Plugin for fluentbit | https://docs.fluentbit.io/manual/pipeline/outputs/kafka |
Functions
These call can all be made from the kafka-connect pod
Login to the kafka-connect pod
kubectl exec -it kafka-cp-kafka-connect-<ID> -c cp-kafka-connect-server bash
List Connectors
$ curl -s -X GET -H "Content-Type: application/json" http://kafka-cp-kafka-connect:8083/connectors ["azure-sink-connector"]
Get connector details
$ curl -s -X GET -H "Content-Type: application/json" http://kafka-cp-kafka-connect:8083/connectors/azure-sink-connector
{
"name": "azure-sink-connector",
"config": {
"connector.class": "io.kafka.connect.log.anlaytics.sink.LogAnalyticsSinkConnector",
"workspace.id": "7e0d2c8e-a46c-4fd9-b274-4b07f0ba555c",
"topics": "john-test",
"value.converter.schemas.enable": "false",
"name": "azure-sink-connector",
"workspace.key": "y3n6lvRaKhDIaV6UuGn6+nuh/BoRsQI0fy9S13ZdrL/w56LUOuqrRK3ajAAnxjo8W4PAzxId0V09bJWxmtrNLA==",
"value.converter": "org.apache.kafka.connect.json.JsonConverter",
"key.converter": "org.apache.kafka.connect.storage.StringConverter"
},
"tasks": [
{
"connector": "azure-sink-connector",
"task": 0
}
],
"type": "sink"
}
Delete a Connector
curl -s -X DELETE -H "Content-Type: application/json" http://kafka-cp-kafka-connect:8083/connectors/azure-sink-connector
Send Message to a topic
echo '{"test": 213}'| kafka-console-producer --broker-list kafka-cp-kafka-headless:9092 --topic john-test
References
| Reference | URL |
|---|---|
| Apache Kafka in 5 minutes | https://www.youtube.com/watch?v=PzPXRmVHMxI |
| Nokia Learning - Kafka | https://nokialearn.csod.com/ui/lms-learning-details/app/course/dc425d19-5642-535f-916c-211768f90a00 |
| Kafka Topics, Partitions and Offsets Explained | https://www.youtube.com/watch?v=_q1IjK5jjyU |
| Kafka Helm Charts | https://github.com/confluentinc/cp-helm-charts |
Confluent for Kubernetes | https://docs.confluent.io/operator/current/overview.html#operator-about-intro |